Simon Says
I recently watched a video about Simon Peyton's Jones take on Haskell. (In case you don't know Simon, he's a prolific scientist in the field of functional programming concepts) One thing from the video really struck me, it was the diagram created comparing safety/purity with utility.

The video was recorded 11 years ago so the video quality isn't particularly great. However, Simon put C and C# in the top left indicating it was an extremely useful, but unsafe language. He then put Haskell in the bottom right indicating it was a safe language, but not particularly useful. In this context safety is defined by how "effectful" the language is. More effects are less safe and more pure and controlled transactions are more safe.
"A program with no effect, has no point in running. You have this black box and you press "go", it gets hot but produces no output. (...) We figured out how to combine, in a single language, (...) effectful computation and effect-free ones without making them pollute each other."
- Simon Peyton Jones
He then continues to explain that languages are trying to move towards the top right. Haskell would do this by moving up (increasing utility) and other languages would do this by moving right (increasing safety). Simon notes that many languages are moving right via "cross pollination" of ideas from and to Haskell. Despite this commentary being documented 11 years ago, it holds up very well today. However, it now seems we have a new contender for the top right, Rust.
You can watch the full video here
Rust
Rust is a systems programming language that is designed to be safe, fast, and concurrent. It is a language that is intended to be a replacement for C/C++. I'm sure you've heard terms like "blazing fast" and "memory safe" thrown around when talking about Rust. However, one aspect that is often overlooked is the design influence Rust has had. More specifically, the way purity-focused design choices of Haskell have influenced Rust.
All of Rust's Influences
I don't cover all of the langauge influences for rust in this post. You can find the official documented influences to rust here.
Type Classes
Typeclasses are the main mechanism for allowing ad-hoc polymorphism in haskell and it makes a mostly complete return in rust. Typeclasses can be thought of as interfaces in other languages. They are, however, more powerful. Rather than coupling interface implementation with a data declaration, typeclasses can be opted into after the fact. This allows for a more flexible and powerful design while also eliminating the need for upcasting and downcasting in most scenarios.
The influence from haskell is extremely clear here. Let's take a look at some examples.
class Driveable a where
drive :: a -> String
data Car = Car
instance Driveable Car where
drive _ = "Vroom vroom"trait Driveable {
fn drive(&self) -> String;
}
struct Car;
impl Driveable for Car {
fn drive(&self) -> String {
"Vroom vroom".to_string()
}
}Rust even has blanket implementations for typeclasses.
instance Driveable a => Driveable (Maybe a) where
drive (Just a) = drive a
drive Nothing = "Nothing to drive"impl<T: Driveable> Driveable for Option<T> {
fn drive(&self) -> String {
if let Some(a) = self {
return a.drive()
}
"Nothing to drive".to_string()
}
}Pattern Matching in Rust
Rust has pattern matching like Haskell. In my example I use if let ... to pattern match on the Option type as it is the most concise for matching a specific case. However you can also use match to pattern match on multiple cases.
match self {
Some(a) => a.drive(),
None => "Nothing to drive".to_string(),
}Type Inference
Type inference is what allows developers to omit type information in areas where the compiler can infer the type. Both Rust and Haskell take advantage of the HM type inference algorithm. This results in less explicit type annotations needed overall.
Let's take a look at this in action.
First let's introduce a new data structure in both rust and haskell that defines a person.
struct Person {
age: u32,
}newtype Person = Person { age :: Int }Each language offers a typeclass to convert a string to a data structure. For rust we implement FromStr and for haskell we create an instance of Read.
impl FromStr for Person {
type Err = ();
fn from_str(s: &str) -> Result<Self, Self::Err> {
Ok(Person {
age: s.parse().unwrap(),
})
}
}instance Read Person where
readsPrec _ s = [(Person (read s), "")]Now when we parse a string into a person we can omit the type information.
fn introduce(person: &Person) {
println!("I am {} years old", person.age);
}
fn main() {
let person = "3".parse().unwrap(); // Inferred to be a Person
let p_age = person.age; // u32 of 3
introduce(&num);
}introduce :: Person -> IO ()
introduce person = putStrLn $ "I am " ++ show (age person) ++ " years old"
main = do
let person = parse "3" -- Inferred to be a Person
let pAge = age person -- Int of 3
introduce personThe compiler successfully picks up the type of p_age and pAge without us having to explicitly define it.
But how does it know which type we wanted? How did it know we wanted a Person rather than a String or any other type for that matter?
Unlike other languages, Rust and Haskell types can be inferred by usage. In the example above both languages deduce the type of person because it is
used as a parameter in introduce. Since introduce expects a Person the compiler can deduce that person must be a Person. The best part is we don't need
to know how the type inference algorithm works to take advantage of it.
Let's take a look at a similar example in Java.
public class Person {
public int age;
}
public class TypeInference {
public static void introduce(Person person) {
System.out.println("I am " + person.age + " years old");
}
public static Person parsePerson(String s) {
var person = new Person();
person.age = Integer.parseInt(s);
return person;
}
public static void main(String[] args) {
var person = parsePerson("3");
var pAge = person.age;
introduce(person);
}
}In Java we have to explicitly define a method for parsing a Person. This is because Java uses local type inference. All type information is captured at the declaration site. This means that the compiler has no way of knowing what type we want until we 1) use explicit annotations or 2) provide a value that can be used to infer the type. This is
less robust than Haskell and Rust since the method is proprietary and not polymorphic (parse() and read can be reused in multiple contexts for different data structures unlike parsePerson).
Ad-Hoc Polymorphism
There are two forms of polymorphism used in programming languages
- Ad-Hoc Polymorphism
- Parametric Polymorphism
Ad-Hoc polymorphism is polymorphism where the behavior of a function/method changes based on it's arguments. In our examples above the return value of read and parse have a different return type based on the inferred type of the variable person.
Parametric polymorphism is polymorphism where the behavior of a function/method does not change based on it's arguments. In our examples above the return value of introduce and Java's parsePerson is always the same regardless of the type of person. However, it can work on any type that is covariant with Person.
Despite this, Java does support ad-hoc polymorphism via overloading. For example, System.out.println has multiple implementations based on the type of the argument. Overloading is less extensible than the typeclass approach because only the owner of the type can define new implementations. In Haskell and Rust anyone can define a new implementation for a typeclass on any object they own.
Monads
Rust follows some of the ubiquitous monads found in haskell, for example Option is analogous to Maybe and Result is analogous to Either. But what's the point of using monads? Why not have manual null checks, and try-catch?. We use monads because they allow side-effects in a controlled manner. We can traverse data structures with chains of possibly missing data with confidence.
Option<T>
struct D {
e: u32,
}
struct C {
d: Option<D>,
}
struct B {
c: Option<C>,
}
struct A {
b: Option<B>,
}
let x = A {
b: Some(B {
c: None,
}),
};
// Safely resolves to 0
let y = x.b.and_then(|b| b.c).and_then(|c| c.d).and_then(|d| d.e).unwrap_or(0);Even with the minefield of possibly missing values the Option monad gives us the safety we need to traverse the data structure.
Result<T, E>
Result in rust is an even more interesting case of haskell influence. Unlike Option, Results have a syntactic sugar ? for safely "unwrapping" the value. However upon closer inspection you may realize that ? is just the monadic bind operator often used in haskell.
newtype Error = Error String
foo :: Either Error Int
foo = do
x <- Right 5 -- <- is the bind operator
let y = 6 + x -- We can treat x as a normal `Int` due to the monadic bind
return y -- return is the wrapping methodstruct Error(String);
fn foo() -> Result<i32, Error> {
let x = Ok(5)?; // ? is the bind operator
let y = x + 6; // We can treat x as a normal `i32` due to the monadic bind
Ok(y) // `Ok` is the wrapping method
}It's crazy to see these comparisons, because rust in certain scenarios almost "borrows" the do blocks from haskell, and it does it in a way that feels at home for both imperative and functional programmers. It's also worth noting that the ? operator is not the only way to unwrap a Result. You can also use the match expression. But for the sake of brevity rust programmers and haskell programmers have embraced syntactic sugar. Overall these monads shows how the "safe" paradigms of haskell have influenced rust.
Algebraic Data Types
Algebraic data types are highly useful for modeling data. I'm not going to compare and contrast rust and haskell here, instead you can take a look at my other blog post alebraic data types
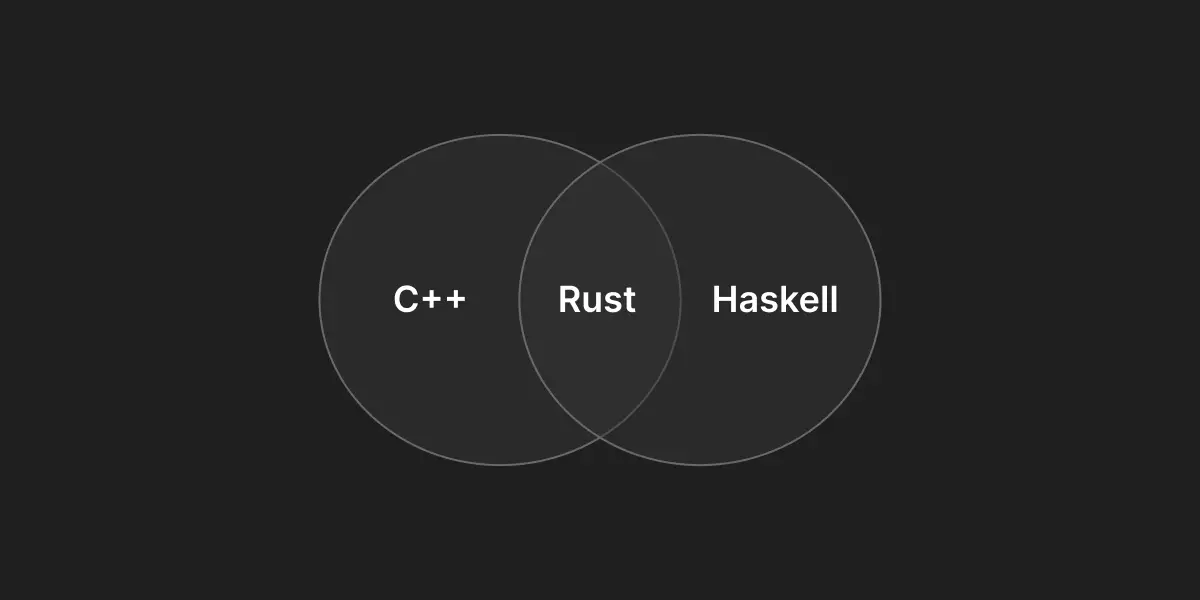
Conclusion - Rust: The intersection of Haskell and C/C++
I am of the firm opinion that rust is the language that finally gives us the idealistic "top right" corner of Simon's diagram. However rust may be considered the first however it most likely won't be the last. The cross pollination of ideas between languages in completely different paradigms has benefited us all. In conclusion it's important to remind ourselves that no one language has all the answers, but we can learn from each other and build better languages.